理解套接字

理解套接字
权双一、套接字概述
网络编程就是编写程序,使两台联网的计算机互相交换数据。计算机操作系统会提供名为套接字(Socket)的部件,套接字是网络数据传输用的软件设备,即使对网络数据传输原理不太熟悉,我们也能通过套接字完成数据传输。
网络套接字(Socket)是计算机通信的基石,它抽象了网络中不同主机上应用进程之间的双向通信端点。简单来说,套接字就像两个设备间的“虚拟管道”——应用程序通过它向网络协议栈发送数据,再经由物理设备传输到目标主机。
核心功能:
- 端点标识:通过“IP地址+端口号”唯一标识通信双方(例如
192.168.1.100:10000) - 协议抽象:屏蔽底层网络协议细节,开发者只需关注数据收发逻辑
- 多协议支持:适配TCP、UDP等不同传输层协议,满足可靠传输或高效传输需求
二、文件描述符
文件描述符(File Descriptor)是Linux系统中用于访问文件或I/O资源的核心概念,其本质是一个非负整数,由内核动态分配并维护。在Linux中,一切皆文件(包括设备、管道、网络套接字),文件描述符为这些资源的访问提供了统一的接口。当进程打开文件、创建套接字或设备时,内核返回一个文件描述符作为操作句柄。
系统预留了三个默认描述符,作为标准输入输出及标准错误的文件描述符:
- 0:标准输入
- 1:标准输出
- 2:标准错误输出
文件和套接字一般经过创建过程才会被分配文件描述符,而上面的3种输入输出文件描述符,即使未经过特殊的创建过程,程序开始运行后也会被自动分配文件描述符。
下面代码将会创建文件和套接字,并用整数保存文件描述符的值。这段代码设计socket()函数的调用,我们这里还没有讲到,不过没关系,这里我们只需知道socket()函数返回值是一个文件描述符即可,open()函数同理。
|
输出:
file descriptor 1:3. |
从输出的文件描述符数值可以发现,描述符从3开始,由小到大依次编号。这是因为0,1,2是分配给标准IO的描述符,我们上面有提到,0,1,2默认描述符,即使未经过创建过程,程序开始运行后也会被自动分配默认文件描述符。
三、网络地址与端口号
3.1网络地址
为使计算机连接到网络并可以收发数据,必须向计算机分配IP地址。IP地址分为两类。
- IPv4(Internet Protocol version 4),4字节地址族
- IPv6(Internet Protocol version 6),6字节地址族
IPv4和IPv6的差别主要表现在IP地址所占用的字节数,IPv6是为了应对IP地址不足的问题而提出的标准,目前通用的地址族为IPv4。
IPv4标准的4字节IP地址分为网络地址和主机地址,分为A、B、C、D、E等类型。
| 类别 | 网络位长度 | 地址范围 | 默认子网掩码 |
|---|---|---|---|
| A类 | 8位(第1字节) | 1.0.0.0 – 126.255.255.255 |
255.0.0.0 |
| B类 | 16位(前2字节) | 128.0.0.0 – 191.255.255.255 |
255.255.0.0 |
| C类 | 24位(前3字节) | 192.0.0.0 – 223.255.255.255 |
255.255.255.0 |
| D类 | 无固定网络位 | 224.0.0.1 – 239.255.255.255 |
无子网掩码 |
| E类 | 保留 | 240.0.0.0 – 255.255.255.255 |
未分配 |
以C类IP地址为例,当向指定IP地址传输数据时,并非一开始就查找IPv4协议的4字节IP地址寻找目标主机,而是先只查找4字节IP地址中的网络地址(网络ID),先把数据传输到网络地址所在的网络(通常为路由器或交换机),然后再查找主机地址(主机ID),数据便可顺利发送到目标计算机。
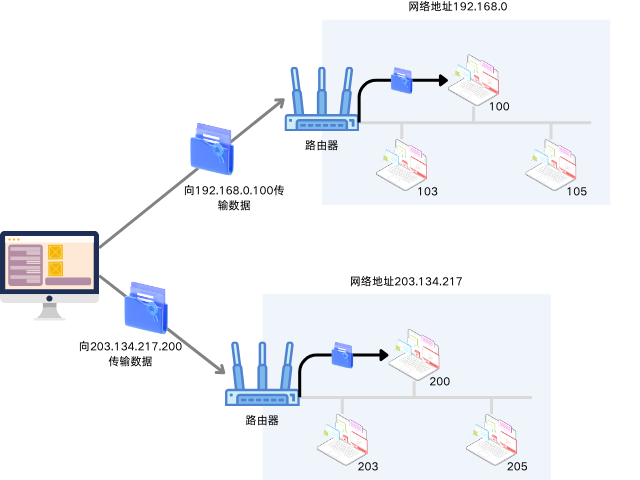
下图展示了基于IP地址的数据传输过程。某主机向192.168.0.100和203.134.217.200传输数据,其中192.168.0和203.134.217为该网络的网络地址(网络ID)。最先,数据便传输到了所在网络的路由器或交换机,最后由接收数据的路由器根据数据主机地址(主机ID)向目标主机传输数据。
3.2 网络ID与主机ID分界
**方法1:**只需通过IP地址的第一个字节就可判断网络地址(网络ID)和主机地址(主机ID)所占用字节数的分配,即可判断IP地址的类型。
- A类(网络地址1字节,主机地址3字节)地址首字节范围:0~127,
- B类(网络地址2字节,主机地址2字节)地址首字节范围:128~191
- C类(网络地址3字节,主机地址1字节)地址首字节范围:192~223
**方法2:**还可以通过IP地址的首位进行判断。
- A类地址的首位以0开始
- B类地址的前2位以10开始
- C类地址的前3位以110开始
方法2可能乍一看有些难以理解,我们不妨转换以下格式。先以101.168.0.100为例,把它转化为二进制的表示方法,可表示为01100101.10101000.00000000.01100100,可以看到,101.168.0.100的首位为0,故101.168.0.100为A类地址。相信解释到这里,大家可以轻松理解方法2的判别方式了。
3.3端口号
端口号是计算机网络中用于标识同一设备上不同应用程序或服务的逻辑地址,由16位整数(0-65535)构成。IP地址用于区分计算机,只要有IP地址就可以向目标主机传输数据,但是仅仅依靠IP地址并不能顺利完成网络通信,还需要端口号才能完成。
当我们使用笔记本听歌的同时在浏览网页查资料,这种情况下至少需要1个接收视频数据的套接字和1个接收网页信息的套接字。问题在于怎么区分二者数据,传送到笔记本电脑的网络数据是发送给播放器,还是发送给浏览器?这时候便体现出了端口号的重要性!
计算机中配有NIC(Network Interface Card,网络接口卡),NIC是计算机与网络之间进行数据通信的硬件设备,负责将数据转换为可通过网络传输的信号。通过NIC向计算机内部传输数据时会使用到IP,操作系统负责把传递到内部的数据分配给套接字,这个时候就需要用到端口号。可以这样理解,通过NIC接收到的数据包含有端口号,操作系统就是根据端口号把数据传送给相应套接字。
1.端口号作用
端口号就是为了在同一操作系统内区分不同套接字而设置的。一台设备可能同时运行多个网络服务(如Web服务器、数据库、游戏),端口号帮助操作系统将数据精准路由到对应程序。
2.端口号分类
端口号由16位构成,可分配的端口号范围是0~65535,但是0~1023是知名端口(Well-known PORT),一般分配给特定应用程序。当用户需要使用端口号时,应分配知名端口以外的端口号。
3.端口号分配
由于端口号是用来区分不同套接字的,因此无法将1个端口号分配给不同的套接字。但是,虽然端口号不能重复,TCP套接字和UDP套接字不会共用端口号。举个例子,如果某个TCP套接字使用10000号端口,则其他TCP套接字无法使用该端口,但UDP套接字仍然可以使用该端口。
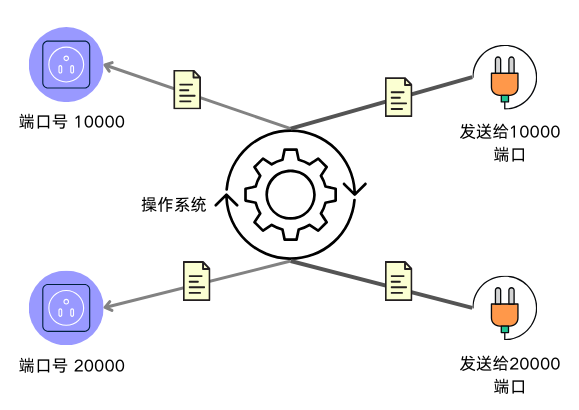
操作系统是根据应用程序端口号进行数据传输的接口匹配。
四、网络字节序
在计算机网络通信中,不同硬件架构的主机可能采用不同的字节序(大端或小端),这会导致多字节数据(如整数、浮点数)的存储顺序不一致。若不对字节序进行统一,数据传输时会出现严重错误。网络字节序正是为解决这一问题而生的标准化方案,它采用大端模式(Big-Endian)作为数据传输的统一格式。
4.1 字节序的本质与分类
字节序定义了多字节数据在内存中的存储顺序,分为两种类型:
大端模式(Big-Endian)
- 特点:高位字节存储在低地址,低位字节存储在高地址
- 示例:数值 0x12345678 存储为12 34 56 78(地址从低到高)
小端模式(Little-Endian)
- 特点:低位字节存储在低地址,高位字节存储在高地址。
- 示例:数值 0x12345678 存储为78 56 34 12(地址从低到高)
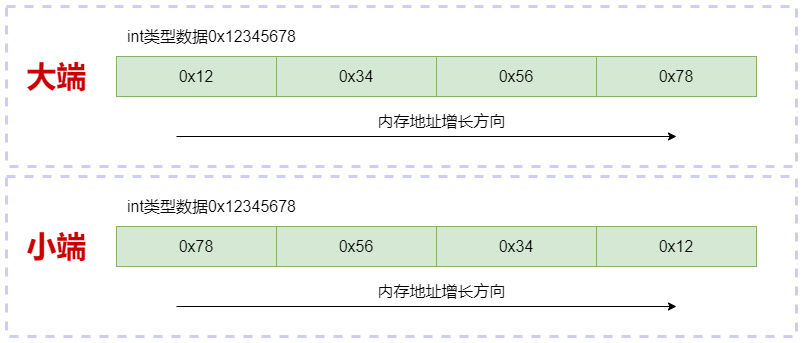
仅凭描述很难解释清楚。如图片所示,假设内存中保存一个int类型的变量0x12345678,0x12为最高位字节,0x78是最低位字节。在大端序中先保存最高位字节0x12(最高位字节0x12存放在内存地址的低地址)。而小端序正好相反,先保存最低字节0x78(最低位字节0x78存放在内存地址的低地址)。
由于不同CPU的数据保存方式不同(大端或小端),因此不同CPU的主机字节序(Host Byte Order)也可能不相同。如果不进行数据格式的转换,在两台计算机网络通信的过程中可能就会出现数据解析问题。

大端系统在发送数据0x12345678时未考虑字节序问题,直接按照0x12、0x34、0x56、0x78从低地址到高地址顺序发送,结果在接收端的小端系统以小端的方式进行保存数据,因此小端序接收到的数据变成0x78563412。因此,在通过网络传输数据时应约定统一方式,这种约定称为网络字节序(Network Byte Order),网络字节序使用大端序。
在进行网络通信时,应先把数据数组转化为大端序格式,再进行网络传输。在接收数据时,应识别该数据为网络字节序格式,小端序系统传输数据时应转化为大断序排列方式。
4.2 字节序转换
下面介绍Socket中用于帮助转换字节序的函数,函数定义如下:
unsigned short htons(unsigned short); |
观察函数名,h代表主机字节序,n代表网络字节序,s代表short类型,l代表long类型。通常,以s作为后缀的函数中,s代表两个字节short,因此用于端口号转换,以l作为后续的函数中,l代表4个字节的long,因此用于IP地址的转换。
下表详述Socket提供字节序转换函数:
| 函数 | 功能描述 | 适用场景 |
|---|---|---|
htons() |
将16位短整型主机序转为网络序 | 端口号转换(如8080) |
htonl() |
将32位长整型主机序转为网络序 | IP地址转换 |
ntohs() |
将16位短整型网络序转为主机序 | 接收端解析端口号 |
ntohl() |
将32位长整型网络序转为主机序 | 接收端解析IP地址 |
讲到这里,相比大家一定有个疑惑,如果我们使用的系统是大端序的,是否还需要进行网络字节序的转换?其实是不需要进行转换的,但是为了程序的可移植性考虑,还是推荐进行网络字节序的转换,这样便实现了与字节序无关的统一代码。在大端序系统中进行主机序到网络序的转换,实际相当于没有做任何操作,但却使得我们写的代码更加标准。
下面来看一段字节序转换函数的示例代码:
|
输出:
Host ordered port:0x1234. |
五、地址信息分配
5.1 地址信息的表示
5.2 网络地址初始化
六、套接字创建流程
6.1 服务器端流程
网络编程中接受连接请求的套接字创建过程可整理如下:
- 第一步,调用Socket函数创建套接字
- 第二步,调用棒的函数分配IP地址和端口号
- 第三步,调用listen函数转为可接收请求状态
- 第四步,调用accept函数受理连接请求
记住并掌握这些步骤,就相当于为套接字编程勾勒好了轮廓。
6.2 客户端流程
七、结束语
总之,想要顺利完成网络通信,就要知道目的应用程序(应用程序套接字)的地址,该地址由IP地址和端口号共同构成。