
CUDA简介
这一节是本课程的第一课,主要从概念上让大家了解什么是
GPU、什么是CUDA。从今天开始,大家将和我一起探索CUDA编程,这一路也许并不轻松,希望大家能有所收获!.
欢迎大家进入我的哔哩哔哩频道进行学习!
1 GPU硬件平台
1.1 什么是GPU
GPU意为图形处理器,也常被称为显卡,GPU最早主要是进行图形处理的。如今深度学习大火,GPU高效的并行计算能力充分被发掘,GPU在AI应用上大放异彩。GPU拥有更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,与GPU对应的一个概念是CPU,但CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务,CPU更擅长数据缓存和流程控制。

1.2 GPU性能
主要GPU性能指标:
-
核心数量:为GPU提供计算能力的硬件单元,核心数量越多,可并行运算的线程越多,计算的峰值越高;
-
GPU显存容量:显存容量决定着显存临时存储数据的多少,大显存能减少读取数据的次数,降低延迟,可类比CPU的内存;
-
GPU计算峰值:每块显卡都会给出显卡的GPU计算峰值,这是一个理论值,代表GPU的最大计算能力,一般实际运行是达不到这个数值的;
-
显存带宽:GPU包含运算单元和显存,显存带宽就是运算单元和显存之间的通信速率,显存带宽越大,代表数据交换的速度越快,性能越高。
1.3 CPU+GPU异构架构
GPU不能单独进行工作,GPU相当于CPU的协处理器,由CPU进行调度。CPU+GPU组成异构计算架构,CPU具有单核高频的特性,适合运行逻辑复杂的程序,而对大量数据的运算就不是那么擅长了,与CPU相比,GPU虽然单个内核频率较低,但可调用的运算核心更多,在并行运算能力方面拥有显著优势。在设计上,GPU将更多资源分配给执行单元,而CPU则拥有复杂的控制单元和缓存,因此GPU更适合于负责高速密集、可并行计算的任务。
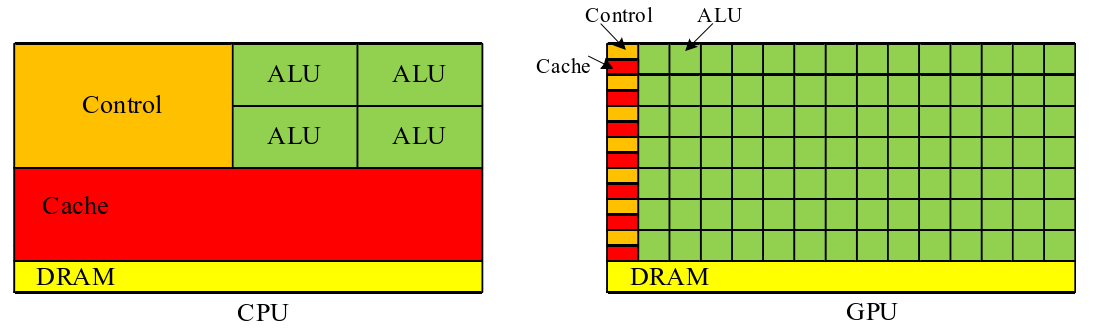
由这个图可以看出,CPU中用于Cache存储和Control控制的晶体管占晶体管总数的绝大多数,而GPU中用于ALU算术逻辑单元的晶体管占大多数。CPU是专为高效处理复杂任务而设计,具备出色的计算和逻辑处理能力,能够应对各种复杂的计算需求。GPU 拥有数千个小型内核,其数量因型号和应用不同而异,这种结构使得GPU特别适合于并行处理。GPU能够同时处理多个并行任务,因此在处理图形和数据计算工作负载上,其速度远超CPU,GPU的内部结构决定了GPU的功能和独特能力。
CPU和GPU都有自己的DRAM(dynamic random-access memory,动态随机存取内存),它们之间一般由PCIe总线(peripheral component interconnect express bus)连接。
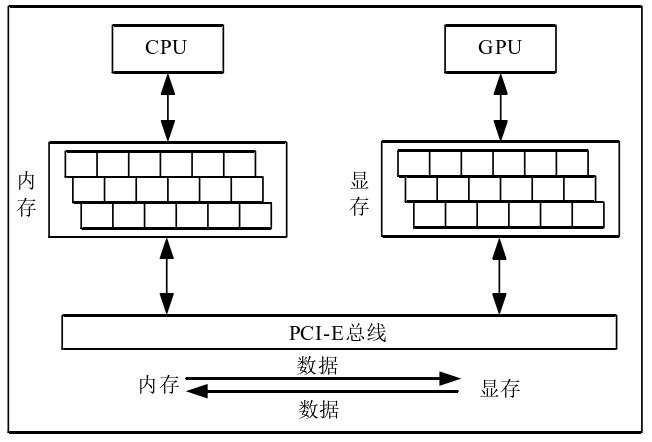
如上图所示,CPU与GPU的信息交互过程通过PCIe总线实现,CPU将内存中的数据传递给GPU,GPU从显存中读取这些数据并进行处理,将处理后的数据再通过PCIe总线传回 CPU的内存中,从而完成一次完整的信息交互循环。
这里多说一点,PCIe总线上的数据传输速率相对来说是比较慢的,也就是说一个不那么复杂的任务,CPU和GPU数据传输的时间可能远远大于GPU计算的时间,所以在一些小型任务上,应用GPU也未必会起到加速作用。
在由CPU+GPU构成的异构计算平台中,通常将起控制作用的 CPU 称为主机(host),将起加速作用的 GPU 称为设备(device)。所以在今后,说到主机就是指CPU,说到设备就是指GPU。
异构应用程序由两部分组成:
- Host code
- Device code
主机代码在CPU上运行,设备代码在GPU上运行。在异构平台上执行的应用程序通常由CPU初始化。CPU代码负责在设备上加载计算密集型任务之前管理设备的环境、代码和数据。
在计算密集型应用中,程序段通常具有丰富的数据并行性,GPU用于加速这部分数据并行性的执行。当一个与 CPU 物理上分离的硬件组件用于加速应用程序的计算密集型部分时,它被称为硬件加速器。GPU可以说是硬件加速器最常见的例子。
1.4 GPU硬件架构
从2006年推出的Tesla架构开始,英伟达公司在GPU架构的发展上取得了显著的进步,并不断推陈出新,于2010年发布了Fermi架构,2012年发布了Kepler架构,2014年再度升级至Maxwell架构。此后,2016年的Pascal、2017年的Volta、2018年的Turing架构接连问世,进一步提升了GPU的性能和效率。在2020年,推出了Ampere架构, 2022年,英伟达更是推出了Hopper和Ada Lovelace两大全新架构,2024年发布了具有划时代意义Blackwell架构,为GPU技术注入了新的活力。这些架构不仅增强了GPU的计算能力,还提高了其可编程性,这推动了GPU在图形渲染、人工智能和高性能计算等领域的应用。
在GPU硬件架构中,不同的架构之间工艺水平存在差异,但它们的内部硬件结构在本质上并无显著差别。在GPU硬件结构组成中,CUDA核心是其核心计算单元,能处理各种数学和逻辑运算,对于复杂任务具有高运算效率和能效。除了CUDA核心,该结构中还包括复杂的内存系统,如L1、L2高速缓存和共享内存等。这些内存组件的主要功能是存储数据和指令,从而减少GPU访问主存的延迟,提高内存访问效率。这些组件与若干个流多处理器(Stream Multiprocessor,SM)和其他核心组件协同工作,实现了高效的并行计算和内存访问,进一步提升了GPU的性能和能效。每个SM又进一步由多个流处理器(Stream Processor,SP) 和其他运算单元组成,SP是GPU最基本的处理单元。
2 CUDA介绍
这一小节从什么是CUDA、CUDA编程语言进行阐述。
2.1 什么是CUDA
CUDA是英伟达于2006年推出的一种并行计算平台和编程模型,它的全称为Compute Unified Device Architecture,即统一计算架构。这一平台通过提供编程接口来操作GPU硬件,支持多种编程语言,如C/C++、Python和Fortran,以实现并行计算任务的加速。CUDA被广泛应用于计算密集型程序中,从而提高程序的计算速度。
在CUDA的软件架构中,开发人员可以使用支持的编程语言来编写并行计算任务。下图展示了CUDA的软件架构示意图。CUDA提供了一种分层的架构,其中包括CUDA Driver、CUDA Runtime、CUDA Libraries。CUDA Driver是与GPU硬件通信的低层软件组件。它负责管理和调度GPU上的计算任务,以及与操作系统进行交互,开发人员可以使用这些组件来控制计算任务的执行、内存的分配和释放,以及与GPU设备的通信。开发人员可以使用CUDA Runtime来管理设备内存、启动并行线程(称为CUDA核函数)以及进行数据传输等操作。 CUDA Libraries是一系列预先编译好的函数库,提供了常见的数学运算、图像处 理、线性代数、信号处理等领域的函数和算法实现。
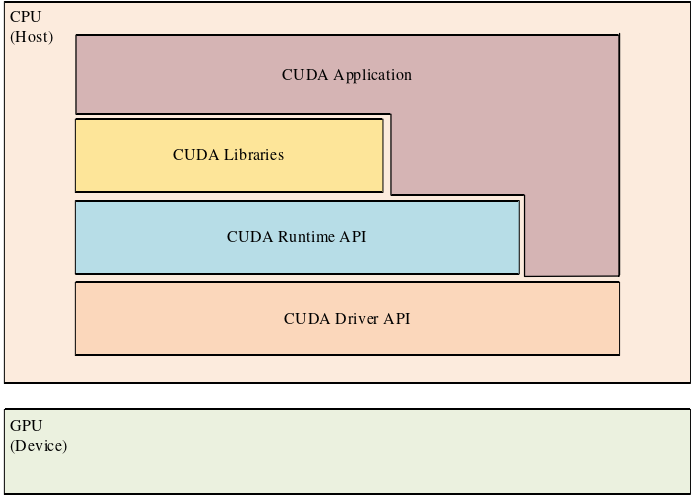
CUDA运行期环境是为开发者提供了与GPU交互的接口。它包括一些用于硬件存储和计算控制的函数,允许开发者动态地管理GPU上的任务和数据。CUDA运行期环境使得开发者能够更灵活地控制GPU上的并行计算,从而实现高性能的计算任务。
CUDA驱动是与GPU硬件紧密交互的一层。CUDA驱动提供了直接与GPU硬件通信的接口,允许开发者对硬件进行低级别的控制。这一层通常用于与硬件紧密相关的任务,如设备初始化和内存管理等。
CUDA是建立在NVIDIA的GPU上的一个通用并行计算平台和编程模型。基于GPU的并行计算目前已经是深度学习训练的标配。
2.2 CUDA编程语言
CUDA支持多种编程语言:
- C/C++;
- Fortran;
- Python;
- MATLAB。
本教程基于C/C++语言进行讲解,学习本教程需要对C/C++语言有一定的基础。
3 CPU和GPU在并行处理的优化方向
在了解CPU和GPU的优化方向前,首先需要先掌握几个性能优化方面的重要概念:
- 延迟(lantency):完成一个指令所需要的时间;
- 内存延迟(memory latency):CPU/GPU从内存获取数据所需要的等待时间;
- 吞吐量(throughput):单位时间内可以执行的指令数;
- 多线程(multi-threading):多线程处理。
3.1 CPU优化方向
CPU 设计用于高效、快速地处理各种各样的任务,尤其是复杂的串行任务以及需要快速响应的任务。虽然现代 CPU 有多个核心支持并行(多核并行),但其底层核心本身是强大的通用处理器 (General-Purpose Processor)。核心目标是让单个线程 (或任务) 尽快跑完。
影响CPU运行速度的主要瓶颈是内存延迟(Memory Latency),与CPU主频(GHz 级别,每个时钟周期纳秒级)相比,访问主存储器(DRAM)的速度非常慢 (通常需要几十甚至几百纳秒)。
因此:
CPU优化方向减少内存延迟(memory latency)。
3.2 GPU优化特点
GPU 设计用于处理大量高度并行、计算密度高、任务相似(数据并行)的工作负载,如图形渲染、科学计算、AI 训练/推理等。其核心数量远超 CPU (成千上万),但每个核心更小、更简单。核心目标是在单位时间内尽可能多地完成任务。
影响GPU运行速度的主要瓶颈是核心多且简单,单个核心的性能不如 CPU 强。关键在于如何同时管理和执行海量的轻量级线程,并高效地喂给它们数据。
因此:
CPU优化方向提高提高吞吐量(throughput)。
这章节就讲到这里,接下来的教程开始正式进入CUDA的实战讲解。
{kind=link}
{kind=link} 微信
支付宝
微信
支付宝